CloneDesk — AI support agents trained on your resolved ticketsGet early access →
AI Support Evaluation
How to Evaluate AI Customer Support Agents: 7 Metrics That Matter in 2026
Chris CholetteFounder, CloneDeskJune 202610 min read
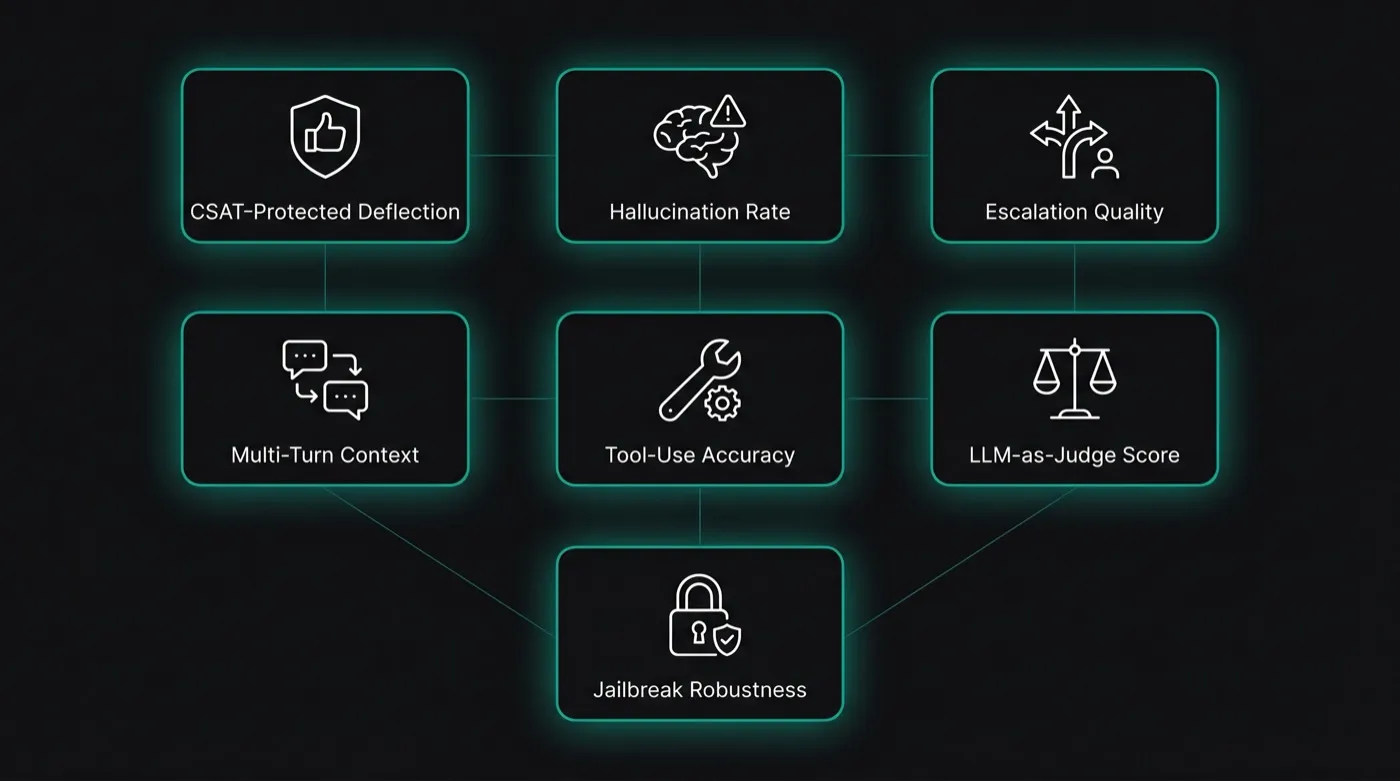
Production AI customer support agents are evaluated by 7 metrics, not 1. Resolution rate matters — but only paired with CSAT-protected deflection, hallucination rate, escalation quality, multi-turn context retention, tool-use accuracy, LLM-as-judge quality scores with bias controls, and jailbreak robustness. Here's how each metric works, what production teams set as targets, and which vendor case studies prove why a single-number evaluation misses six of the seven signals that actually predict whether your AI agent is helping customers or silently failing them.
Seven production-grade signals — measured together, not in isolation. Each metric catches a failure mode the others miss.
Why Resolution Rate Alone Is Misleading
When Zendesk markets AI Agents at 80% resolution and Intercom Fin claims 76%, what does that headline actually measure? Vendor-cited numbers are typically computed against benchmark customer cohorts — high-volume, low-variance ticket mixes (shipping status, password resets, returns) where the AI performs well. In production, the numbers land lower:
Zendesk's own Vagaro case study — 44% AI agent resolution rate, alongside an 87% reduction in resolution time (3 hours to 23 minutes) and a 5-point CSAT lift (from 87% to 92%) over three months.
Intercom Fin in production — documented resolution rates of 45–53% across B2B SaaS deployments, a 23–31 point gap from the marketed 76% claim. See our full breakdown of vendor claims versus production data for both platforms.
Forethought's 2025 AI in CX Benchmark Report (surveying 600+ CX leaders) — dedicated AI point solutions averaged 38% deflection, nearly double the rate of help-desk add-on chatbots but well below the 70–80% vendor headlines.
The deflection-vs-resolution gap isn't proof that resolution rate is "lying." Sixty-seven to eighty-one percent of customers genuinely prefer self-service for routine inquiries, and a well-deflected ticket has real economic value: McKinsey's 2026 AI in Customer Service analysis pegged AI resolutions at $0.46 versus $4.18 per human-handled ticket — a 9× cost reduction. The problem isn't deflection itself. The problem is deflection as a standalone signal.
A high deflection rate that comes with a CSAT decline, a rising re-contact rate, or hallucinations on edge cases is worth less than a lower deflection rate that holds CSAT and escalates intelligently. That's the case for measuring seven metrics. Resolution rate stays — but it's metric #1 of 7, not 1 of 1.
1. CSAT-Protected Deflection
Deflection without escalation context is a vanity metric. CSAT-protected deflection measures resolution without sacrificing customer satisfaction: deflection rate × (1 − CSAT decline). A 60% deflection with a 5-point CSAT drop is worse than 45% deflection with flat CSAT. Most vendors optimize the first and ignore the second.
What it measures
The share of tickets resolved without human handoff, weighted by whether CSAT held up on those interactions.
Production target
CSAT delta within 0.10 of the human baseline. AI-handled tickets average 4.10/5 vs 4.30/5 for human agents (Zendesk CX Trends 2026) — a 0.20-point gap that narrows to 0.05 with proper hybrid escalation flows.
How to measure
Pair every AI-resolved ticket with a 1-question post-resolution CSAT survey. Compute as deflection_rate × (1 − max(0, CSAT_baseline − CSAT_ai)). Track weekly; alert on regression.
Case study
Vagaro lifted CSAT from 87% to 92% while resolving 44% of tickets via Zendesk AI. That's a true 44% × 1.057 = 46.5% CSAT-protected deflection — better than the headline because the AI didn't damage satisfaction.
2. Hallucination Rate
Production hallucination rate benchmarks: under 2% for straightforward FAQs, 3–5% for technical troubleshooting, 5–8% for product recommendations. Measure via RAGAS or DeepEval against a sample of 200+ support conversations. Lakera Guard's hallucination-injection tests typically reveal an additional 8–12% rate when customers attempt jailbreaks.
What it measures
The rate at which the AI confidently asserts an incorrect fact, policy, or instruction.
Why it matters
Unguarded LLMs hallucinate in 15–27% of customer service responses. At production scale, that's thousands of customers per month receiving wrong information delivered with confidence — a trust catastrophe and a regulatory exposure in regulated industries.
Production target
Under 2% on FAQs, under 5% on technical troubleshooting, under 8% on open-ended advice. Healthcare and finance require under 1% with mandatory human verification on high-stakes outputs.
How to measure
Build a golden dataset of 200+ real queries with verified correct answers. Run the agent against this dataset weekly. Compute via RAGAS faithfulness, Openlayer's groundedness check, or DeepEval's hallucination metric.
3. Escalation Quality (Human Override Rate)
Escalation rate is the wrong metric. An AI that escalates everything is no better than a chatbot menu; an AI that escalates nothing hallucinates its way through edge cases. The right question is whether the escalations themselves were correct.
What it measures
Of the tickets the AI sent to humans, how many did the human override (resolved differently from the AI's diagnosis)? And of the tickets the AI resolved itself, how many came back as re-contacts within 7 days?
Production target
Human override rate under 10% on escalated tickets (the AI's handoff context was accurate); re-contact rate under 8% on AI-resolved tickets (the AI's resolution actually held).
How to measure
Instrument the helpdesk to capture the AI's stated diagnosis on every escalated ticket; compare to the human agent's actual resolution. Track re-contacts via ticket reopens and follow-up conversations within 7 days.
Why it matters
Forethought's 2025 benchmark report found teams measuring escalation quality (rather than raw escalation rate) achieved 23% higher overall CSAT — because they could distinguish "AI correctly identified this needed a human" (good) from "AI confidently gave the wrong answer and the customer escalated themselves" (bad).
4. Multi-Turn Context Retention
Errors compound exponentially across conversation turns. A 95% per-turn accuracy means a 5-turn conversation has only 77% end-to-end accuracy (0.955). Losing context forces the customer to re-state their issue, doubling handle time and degrading CSAT by 8–12 percentage points on conversations longer than four turns — exactly where the AI's value should be highest.
What it measures
Across a multi-turn conversation, does the agent reference earlier messages correctly without forcing the customer to repeat themselves?
Production target
≥95% context retention across 5-turn conversations; ≥85% across 10-turn conversations.
How to measure
Build evaluation scenarios with deliberate context dependencies — e.g., customer says "I ordered last Tuesday" in turn 2, then in turn 4 asks "when will it ship?" A correct agent uses the Tuesday context; a context-losing agent asks again. Score binary per turn; compute average across the dataset.
Tooling
Google's Agent Development Kit (ADK), LangChain Memory, and Mem0 provide multi-turn primitives, but the evaluation itself is typically custom. Don't trust framework defaults — write the scenarios for your actual product.
5. Tool-Use Accuracy
Agentic AI for support — the trend driving more than 40% of enterprise applications by the end of 2026 per Gartner — depends entirely on reliable tool use. By 2028, Gartner projects AI agents will intermediate over $15 trillion in B2B purchases. Tool-use accuracy is the difference between an agent that does things and a chatbot that describes doing things.
What it measures
When the AI agent calls an external tool or API (looking up an order, checking inventory, processing a refund), does it select the right tool, pass valid arguments, and use the response correctly?
Production target
≥95% correct tool selection on a verified test set; ≥98% argument validity; ≥99% on the success path of high-frequency tools (e.g., "look up order by ID").
How to measure
Build a tool-use eval suite with ~50 scenarios per tool. For each, define the correct tool, correct arguments, and expected response handling. Score the agent's decisions binary. The simplest implementation is a JSON schema validator wrapped around tool calls.
Architecture note: behavioral fine-tuning produces more deterministic tool selection than RAG. The agent learned which tool the human used in similar past tickets, rather than retrieving a tool-call inference at query time. See what behavioral fine-tuning actually does for the underlying mechanism.
Manual human evaluation doesn't scale past a few hundred conversations. LLM-as-judge frameworks let you evaluate thousands per week — but only if the judge is calibrated. Uncalibrated LLM judges introduce systematic biases that quietly degrade your entire evaluation pipeline.
Fallacy oversight — judges miss logical errors in plausible-sounding outputs
Production target
Cohen's kappa ≥0.85 against human gold labels; verbosity bias correction (normalize by response length); position randomization on pairwise comparisons.
How to measure
Maintain a 100-item human gold-labeled dataset. Run LLM-as-judge on the same items. Compute Cohen's kappa quarterly. Use temperature=0, structured rubrics with explicit criteria, order alternation, and cross-family checks (a Claude judge AND a GPT judge — flag disagreements for human review).
State of the art
The recent arXiv:2510.12462 paper (February 2026) systematically tested 11 bias types across 6 judge models and found state-of-the-art judges are robust to deliberately-biased inputs when bias controls are in place. Without controls, the same judges produce systematically skewed scores. DeepEval and Confident AI ship calibration-aware metrics; RAGAS provides framework-level support for context-aware scoring.
7. Jailbreak / Prompt-Injection Robustness
AI customer support agents handle sensitive customer data, can trigger transactions (refunds, account changes, returns), and shape brand perception. A single successful jailbreak that surfaces a system prompt, generates a false refund authorization, or produces a screenshot-worthy hostile response is a brand event — and increasingly, a compliance event.
What it measures
When adversarial inputs attempt to bypass the agent's guardrails — extracting system prompts, getting the agent to ignore policy, or coaxing it to perform unauthorized actions — does it hold?
Production target
≥95% block rate against known adversarial patterns; under 1% false-positive rate (legitimate but unusual queries blocked); zero successful exfiltration of system prompts in red-team testing.
How to measure
Run a periodic red-team eval using Lakera Guard's prompt-injection benchmark, OWASP LLM Top 10 test patterns, or a custom adversarial dataset built from your own attempted jailbreaks. Measure both block rate and false-positive rate. Industry consensus is that 100% blocking is unrealistic — over-tight guardrails make the agent useless on creative customer queries.
How to Implement the Framework: A 5-Step Playbook
You don't need to deploy seven separate evaluation systems. The metrics share a common foundation — a golden dataset and an evaluation pipeline — and most production teams stand them up in this order:
Build the golden dataset (Week 1). Pull 200 representative resolved tickets from the last 90 days. Spread across complexity tiers (FAQ / standard / complex), categories, and outcomes (resolved / escalated / abandoned). Have a senior support agent label each with: expected resolution, expected tool calls, expected escalation decision, and a 1–5 quality score with rationale.
Set up RAGAS or DeepEval (Week 1). Wire one of these open-source frameworks against your AI agent's outputs. RAGAS is the right choice for RAG-based agents (it scores faithfulness, context precision, context recall). DeepEval is more general — works for RAG and fine-tuned agents both.
Add Openlayer or Confident AI for monitoring (Week 2). These platforms wrap the same metrics in a continuous monitoring layer — you get weekly reports on regression, drift, and outlier conversations rather than ad-hoc evaluation runs.
Add Lakera Guard or equivalent for the security layer (Week 2). This handles the jailbreak metric without requiring you to build adversarial datasets yourself.
Calibrate quarterly, alert weekly (ongoing). Re-label 20 items from your golden dataset each quarter against your current agent's outputs to catch judge drift. Set alerting thresholds for CSAT-protected deflection drops >5 points week-over-week, hallucination rate increases >1 point, and tool-use accuracy drops >2 points.
A small CX engineering team should be able to stand the full pipeline up in 2–3 weeks. The hard part isn't tooling; it's the golden dataset. Don't shortcut it.
Why Behavioral Fine-Tuning Evaluates Differently than RAG
The 7-metric framework applies to any AI customer support architecture — but it produces different shapes of numbers depending on whether the agent is RAG-based or behaviorally fine-tuned.
RAG-based agents (Zendesk AI, Intercom Fin, Forethought-now-part-of-Zendesk, Ada CX) retrieve from a knowledge base at query time and generate a response from whatever they find. Outputs are stochastic across two layers — which documents got retrieved, and how the language model summarized them. The same query asked twice can produce different answers depending on retrieval randomness, embedding-model drift, and chunk-boundary luck. Evaluation has to allow for multiple acceptable outputs, and behavioral consistency scores tend to be lower because the architecture itself is non-deterministic at the answer layer.
Behaviorally fine-tuned agents (CloneDesk's approach) encode the resolution patterns from your team's historical resolved tickets directly into model weights via LoRA or QLoRA adapters. The agent learned what your top support reps actually do — the escalation logic, the tone, the edge-case handling. At inference time, the answer comes from the weights, not from retrieval. Evaluation is more deterministic: the same query produces the same answer (modulo temperature), behavioral consistency scores are higher, and you can golden-label outputs with single expected answers rather than distributions.
What's the single most important AI customer support metric?
There isn't one. Resolution rate alone is misleading because it can be gamed by an agent that over-deflects or confidently gives wrong answers. The honest answer is a 7-metric framework: CSAT-protected deflection, hallucination rate, escalation quality, multi-turn context retention, tool-use accuracy, LLM-as-judge quality score with bias controls, and jailbreak robustness. Each catches a failure mode the others miss.
How is CSAT-protected deflection different from regular deflection rate?
Regular deflection rate counts every ticket the AI closed without human handoff, including the ones where the customer gave up. CSAT-protected deflection weights that number by whether customer satisfaction held up. Computed as deflection_rate × (1 − CSAT_decline). A 60% deflection rate with a 5-point CSAT drop is worse than a 45% deflection rate that holds CSAT flat. Most vendors report the first number; the second is the one that correlates with retention and renewal.
What's an acceptable hallucination rate for production AI support?
Production targets in mid-2026: under 2% for straightforward FAQ tickets, 3–5% for technical troubleshooting, 5–8% for open-ended product recommendations. Unguarded LLMs hallucinate in 15–27% of customer service responses — that's the baseline you're starting from. High-risk industries like healthcare and finance require under 1% with mandatory human verification on high-stakes outputs.
Can I use LLM-as-judge to evaluate my support AI reliably?
Yes, but only with bias controls. Calibrated LLM judges (temperature=0, structured rubrics, order randomization on pairwise comparisons, cross-family checks) can achieve over 90% alignment with human evaluators. Uncalibrated judges introduce verbosity bias (favoring longer responses), position bias, self-preference bias, and fallacy oversight. Always validate quarterly against a 100-item human gold-labeled dataset and compute Cohen's kappa; target ≥0.85.
How do behavioral fine-tuning agents differ in evaluation from RAG agents?
RAG-based agents (Zendesk AI, Intercom Fin, Ada CX, Forethought) are stochastic across two layers — which documents got retrieved, and how the LLM summarized them. The same query asked twice can produce different answers. Behavioral fine-tuning encodes resolution patterns directly into model weights via LoRA, producing more deterministic outputs. That makes evaluation more reliable: the same query produces the same answer (modulo temperature), behavioral consistency scores are higher, and golden datasets can use single expected answers rather than answer distributions.
Which tools should I use to measure these 7 metrics?
Open-source frameworks: RAGAS (RAG-specific faithfulness, context precision, context recall), DeepEval (general-purpose with 14+ LLM-evaluated metrics including hallucination and bias). Continuous monitoring: Openlayer (RAG groundedness checks) or Confident AI (managed DeepEval platform). Security layer: Lakera Guard for prompt-injection and jailbreak robustness. Most production teams combine RAGAS or DeepEval for the metric layer with Openlayer or Confident AI for monitoring, plus Lakera Guard for the security tests.
Early Access
Measure AI Quality. Then Measure the Difference.
CloneDesk's behavioral fine-tuning produces deterministic outputs — easier to evaluate against the 7-metric framework above. See projected accuracy on your actual data before any live traffic moves.